DGX Spark 에 vLLM과 ComfyUI를 Docker Compose로 구성하기
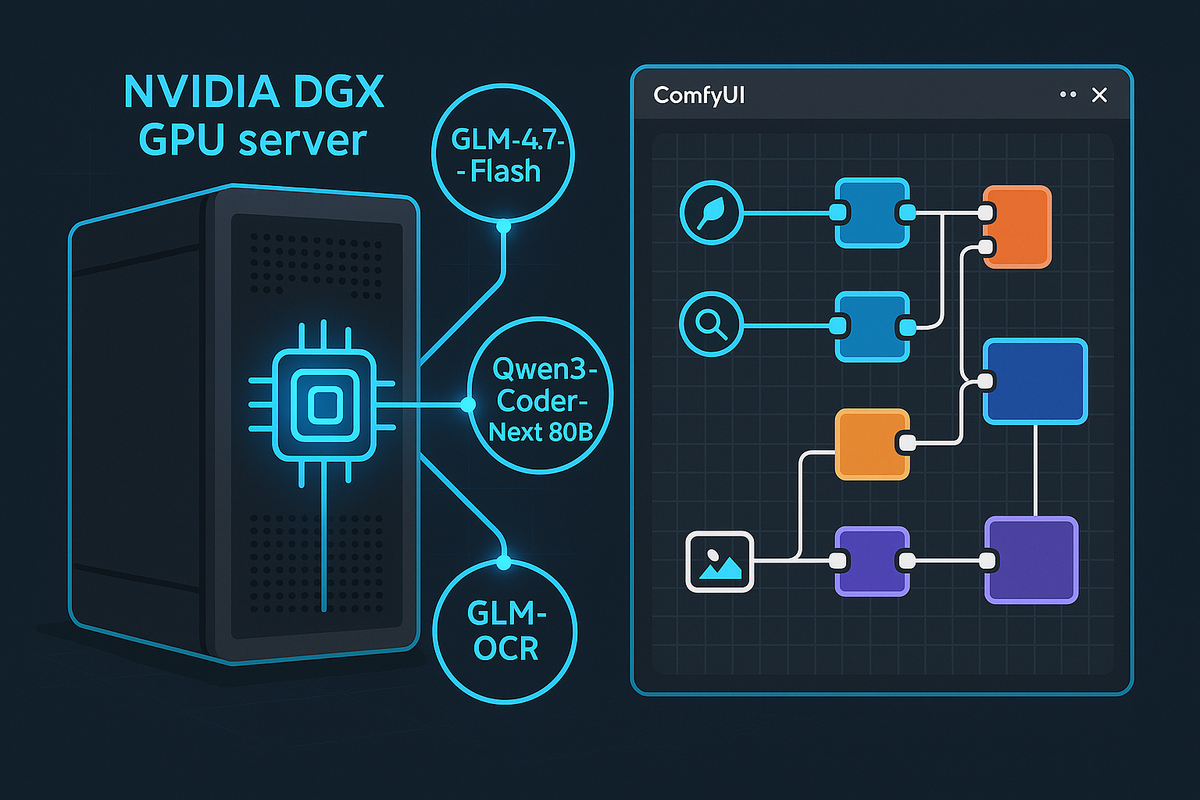
NVIDIA DGX Spark(또는 유사한 고성능 GPU 환경)에서 vLLM과 ComfyUI를 결합하여 GPU 메모리를 효율적으로 나눠 쓰고, 모델을 공유하며 사용하는 최적의 설정을 위한 구성입니다.
이 구성의 핵심은 다음과 같습니다.
- vLLM 백엔드: LLM(텍스트/코드 생성 및 OCR)을 로컬 메모리(RAM)와 GPU 메모리를 혼용하여 serving합니다. (때로는 뒤로 밀림 가능)
- ComfyUI 프론트엔드: vLLM이 관리하는 LLM API를 호출하거나, 시스템 RAM을 활용하여 이미지 생성(Stable Diffusion 등)에 집중합니다.
- 커스텀 노드 설치 자동화: ComfyUI와 모델을 연결해주는 필수 노드들을 컨테이너 구동 시 자동으로 설치합니다.
1. 디렉토리 구조 및 사전 준비
프로젝트 폴더를 생성하고 아래와 같은 구조를 잡습니다.
mkdir ai-dgx-project
cd ai-dgx-project
mkdir models # 모델이 저장될 폴더
mkdir vllm_cache # vLLM 캐시용
mkdir custom_nodes script
필수 사전 준비 (모델 다운로드)
models 폴더 안에 아래 모델들이 들어있어야 합니다. vllm이 자동으로 찾아서 불러오도록 구성했습니다.
- glm-4.7-flash:
THUDM/glm-4-flash(HF 훅/사이트에서 다운로드 필요) - qwen3-coder-next 80b:
Qwen/Qwen2.5-72B-Instruct(가능하면 80B, 부족하면 72B 사용 권장). 이름에 맞게 폴더명 지정 권장.- 예:
models/Qwen3_Coder_80B
- 예:
- glm-ocr:
THUDM/glm-4v(HF 훅/사이트에서 다운로드 필요)
주의: 80B 모델은 VRAM 용량이 매우 큽니다. (일반적으로 4-bit 양자화 기준 최소 80GB 이상의 VRAM과 풍부한 RAM 필요). vLLM은 이를 시스템 RAM(시스템의 일반 RAM)으로 밸런싱합니다.
2. 자동 설치 스크립트 (script/install_custom_nodes.sh)
ComfyUI의 ComfyUI-Glm, ComfyUI-Qwen 등이 설치되어 있지 않으면 LLM이 작동하지 않습니다. 스크립트를 생성해 컨테이너 실행 시 자동으로 설치되게 합니다.
cat > script/install_custom_nodes.sh << 'EOF'
#!/bin/bash
echo "Installing ComfyUI Custom Nodes..."
# ComfyUI-Glm 설치 (GLM 모델 사용용)
if [ ! -f "ComfyUI-Glm/custom_nodes/GLM.py" ]; then
git clone https://github.com/THUDM/ComfyUI-Glm /stable-diffusion/webui/comfyui/custom_nodes/ComfyUI-Glm
fi
# ComfyUI-Qwen 설치 (Qwen 모델 사용용)
if [ ! -d "ComfyUI-Qwen" ]; then
git clone https://github.com/Comfy-Org/ComfyUI-Qwen /stable-diffusion/webui/comfyui/custom_nodes/ComfyUI-Qwen
fi
echo "Custom Nodes installation complete."
EOF
chmod +x script/install_custom_nodes.sh
3. Docker Compose 파일 (docker-compose.yml)
이 구성은 vLLM 컨테이너를 통해 모델을 serving하고, ComfyUI가 이를 자유롭게 호출하도록 설정했습니다.
version: '3.8'
services:
# ---------------------------------------------------------
# Service 1: vLLM Backend (LLM Serving)
# ---------------------------------------------------------
vllm-backend:
image: vllm/vllm-openai:latest
container_name: vllm_service
runtime: nvidia
deploy:
resources:
reservations:
devices:
- driver: nvidia
count: 1 # DGX Spark의 한 대의 GPU를 vLLM에 할당
capabilities: [gpu]
command: >
--model-path /models \
--served-model-name glm-4-flash,qwen3-coder-next-80b,glm-ocr \
--trust-remote-code \
--disable-log-requests \
--port 8000 \
--mm-sampling-method greedy \
--gpu-memory-utilization 0.9 \
--enforce-eager
environment:
- NVIDIA_VISIBLE_DEVICES=all
volumes:
- ./models:/models
- ./vllm_cache:/root/.cache
ports:
- "8000:8000"
stdin_open: true
tty: true
restart: unless-stopped
# ---------------------------------------------------------
# Service 2: ComfyUI Frontend (Image Gen + Analysis)
# ---------------------------------------------------------
comfyui-backend:
image: comfyui/automatic:latest # 최신 공식 이미지
container_name: comfyui_frontend
runtime: nvidia
deploy:
resources:
reservations:
devices:
- driver: nvidia
count: 1
capabilities: [gpu]
environment:
- COMFYUI_DIR=/stable-diffusion/webui
# ComfyUI 사용 옵션 (xformers 메모리 최적화, Prefetch 등)
- CLI_ARGS=--listen 0.0.0.0 --port 8188 --enable-inprogress-prefetch-offload --disable-custom nodes --disable-xformers
volumes:
# 공유 폴더: 모델, 노드, 결과물
- ./models:/stable-diffusion/webui/models
- ./outputs:/stable-diffusion/webui/outputs
- ./custom_nodes:/stable-diffusion/webui/comfyui/custom_nodes
- ./vllm_cache:/root/.cache
# vLLM 경로를 ComfyUI도 읽을 수 있도록 (로컬 노드 필요 시)
- ./script:/script
ports:
- "8188:8188"
command: >
bash -c "
/script/install_custom_nodes.sh &&
python main.py $${CLI_ARGS} --api-base http://vllm-service:8000/v1
"
restart: unless-stopped
depends_on:
- vllm-backend
4. 사용 방법
1) 컨테이너 실행
터미널에서 프로젝트 폴더로 이동 후 실행합니다.
docker-compose up -d
2) ComfyUI 접속
브라우저에서 열면 됩니다:
- URL:
http://localhost:8188
이미지 생성 노드(예: Stable Diffusion 등)를 배치하고 실행합니다.
- GLM 모델 사용 예시: "GLM-4 Talk" 또는 "GLM OCR" 노드를 사용하여 프롬프트를 vLLM 서버에 전송합니다.
- Qwen 모델 사용 예시: "Qwen API" 또는 해당 커스텀 노드를 사용하여 로컬 코드 생성이나 분석을 수행합니다.
주의: ComfyUI가 vLLM API를 연동하여 사용하려면 ComfyUI-Glm과 같은 커스텀 노드가 제대로 설치되어야 합니다. (위 스크립트가 자동 처리하므로 첫 실행 시 다운로드가 완료될 때까지 다소 시간이 소요됩니다.)
3) API 테스트 (vLLM 직접 호출)
vLLM 서버는 OpenAI 호환 API 형태를 지원합니다. 테스트에는 curl이나 Python 등을 사용할 수 있습니다.
curl http://localhost:8000/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "glm-4-flash",
"messages": [{"role": "user", "content": "Hello 80B!"}]
}'
적용 팁
- 메모리 관리: vLLM 컨테이너에서
--gpu-memory-utilization 0.9을 설정하여 GPU의 90%를 사용하고 10%를 ComfyUI 이미지 생성(또는 다른 작업)을 위해 남겼습니다. - 80B 모델 최적화:
qwen3-coder-next 80b모델은 시스템 RAM이 상당히 필요합니다. vLLM은 기본적으로 가중치(model weights)를 GPU VRAM에 올리고, 컨텍스트가 길어지면 CPU RAM으로 오프로딩합니다. RAM이 충분히 크다면 빠르게, 작다면 약간 느릴 수 있습니다. - GLM Flash:
flash모델은 무겁지 않으므로 거의 대부분 GPU VRAM에 상주하여 매우 빠릅니다.



